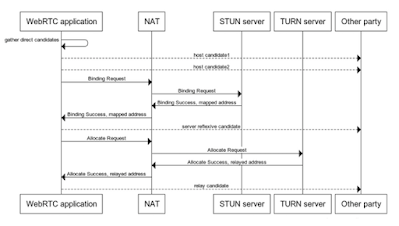
WebRTC applications use the ICE negotiation to discovery the best way to communicate with a remote party. It dynamically finds a pair of candidates (IP address, port and transport, also known as “transport address”) suitable for exchanging media and data.
The most important aspect of this is “dynamically”: a local and a remote transport address are found based on the network conditions at the time of establishing a session. For example, a WebRTC client that normally uses a server reflexive transport address to communicate with an SFU. when running inside the home office, may use a relay transport address over TCP when running inside an office network which limits remote UDP targets. The same configuration (defined as “iceServers” when creating an RTCPeerConnection will work in both cases, producing different outcomes.
This means that a certain portion of WebRTC sessions happen over TURN, i.e. they are relayed through a TURN service, when the choice is left to the client. ‘host’, ‘server reflexive’ and ‘relay’ candidates are left to compete with each other, and the best will win, with the caveat that ‘host’ candidates have the highest priority, and ‘relay’ the lowest. This prioritization originates from the logical assumption that a relayed connection may be less performant than a direct one.
There are cases though when using a TURN service is not optional, but mandatory; an RTCPeerConfiguration setting, ‘iceTransportPolicy’ allows this.
In any case, when TURN is used, it’s important to be able to troubleshoot the session establishment, and this article aims to provide some important guidelines.
These are the key points:
Acquiring the TURN settings
Confirming the reachability of the TURN server
Creating a relay allocation on the TURN server
Setting permissions for using the created allocations
Exchanging ICE connectivity checks over TURN
Exchanging media and/or data over TURN
Acquiring the TURN settings
While STUN servers are typically used without the need for authentication, it’s unlikely that a TURN service can. The resources involved in a TURN service are expensive, in particular in the case of highly scalable and distributed systems, and for this reason are only allowed for authenticated customers.
The required TURN settings are:
These are provided inside the ‘iceServers’ configuration structure passed to the RTCPeerConnection at the moment of creation.
Troubleshooting points
It’s important to verify that the TURN settings are correctly configured; in Chrome, open Developer Tools and check in the JavaScript code that the ‘iceServers’ structure contains valid values.
Check also the ‘iceTransportPolicy’ (which default value is ‘all’).
Confirming the reachability of the TURN server
When the ICE candidates gathering phase begins, the ICE client verifies that the TURN URL defines a reachable service by sending a STUN Binding Request towards the IP and port resolved from the ‘iceServer’ settings.
This request originates from the IP address and port that will be used to access the TURN service, and so it will check that it’s suitable for it.
If the STUN Binding Request is received by the TURN server, then it will respond with a STUN Binding Success, carrying an attribute (XOR-MAPPED-ADDRESS) that tells what source IP and port was seen by the server.
If the STUN Binding Success response is received by the client, then there’s proof that the TURN server is reachable.
For example:
Now it’s possible to negotiate a relay allocation.
Troubleshooting points
In the host running the WebRTC client, take a network trace and verify that the STUN Binding Request is addressed to the expected destination (in particular if the TURN URL required a DNS resolution and so there are multiple IP addresses that could be used).
Verify in the trace that the STUN Binding Success Response is received.
Creating a relay allocation on the TURN server
This is the key element: the client asks the TURN server to become a relay on its behalf.
Here the TURN protocol is used, and the client issues an Allocate Request towards the TURN server. This request must be authenticated, for the reasons discussed earlier, and so it’s challenged with a 401 Unauthenticated response, carrying a realm and a nonce.
The client will use the provided credentials (username and credential), together with the given realm and nonce, to compute a MESSAGE-INTEGRITY attribute and send again the Allocate Request with this attribute.
If the credentials are correct (and also the user is allowed to access the service), then the TURN service will reserve a transport address for that allocation: this is the relay transport address. An Allocate Success Response is transmitted to the client, with a XOR-RELAYED-ADDRESS attribute.
At this point the client has gained a ‘relay’ candidate and transmits it to the remote party through the signalling system in use (this is service-specific and not standardized).
Here’s an example of a successful allocation:
Note that a client may create more than one allocation for the same session; each one will be identified by a different source port, so it will be easily identifiable. You can filter them out with something like ‘stun and udp.port==PORT`, where PORT is the client source port for a transaction you’re interested in.
Troubleshooting points
In the host running the WebRTC client, take a network trace and confirm that there’s an Allocate Success Response.
Wrong credentials
In case of wrong credentials, instead of an Allocate Success Response you’ll see another 401 Unauthenticated response. In this case you must check that the credentials are correct, and the user is authorized to access the service.
Other errors for Allocate Request
Any other error for the Allocate Request will have a detailed error code (in a similar fashion as HTTP or SIP have), so take a note on that and search for its root cause.
Setting permissions for using the created allocations
For security reasons, before media or data is exchanged through the relay, the client must set specific permissions for the remote party.
Once the client has a valid relay allocation, every time it receives an ICE candidate from the remote it must set a permission for the remote IP address.
This is accomplished with a TURN CreatePermission Request. The allocation the permission refers to is implicit from the client source IP address and port. The TURN server will respond with a CreatePermission Success if the request is accepted; note that often a client receives ICE candidates with private or reserved IP addresses: in that case the TURN server will most probably reject the request with a 403 Forbidden response.
Example:
Troubleshooting points
In the host running the WebRTC client, take a network trace and confirm that there’s a CreatePermission Success for at least one of the remote candidates.
If no CreatePermission requests are sent, or none of them is successfully accepted, then no relaying will be possible.
Exchanging ICE connectivity checks over TURN
Once the TURN server is reached, a relay allocation reserved and a permission created, there are the conditions for exchanging ICE connectivity checks over TURN.
These are performed by sending STUN Binding Requests with short term credentials; the peculiarity with TURN is that these Binding Requests are encapsulated inside a TURN Send Indication, addressed to the remote peer.
Wireshark will nicely solve this encapsulation for you, and instead of showing a Send Indication will show you its content, the Binding Request.
The TURN server will relay the Binding Request to the remote peer, performing the relay for the first time. The expected outcome is that the remote entity will respond with a Binding Success, which the TURN server will encapsulate inside a Data Indication and deliver to the client.
If that happens, then the client has learned that the remote candidate is indeed reachable via TURN and that’s a suitable candidate pair for exchanging media and data.
Troubleshooting points
In the host running the WebRTC client, take a network trace and confirm that there are Binding Requests carried over TURN that receive a Binding Success.
If Binding Success responses are not received, then something is preventing it and the best way to investigate is to take network traces on the TURN server host, if possible. Those traces will tell you whether the Binding Requests are correctly leaving the TURN server towards the remote party and whether the Binding Success responses are being received or not.
It’s possible that the remote endpoint is simply unreachable from the TURN service, and in this case the ICE candidates pair will be marked as unusable.
Exchanging media and/or data over TURN
The last fundamental step is the actual exchange of packets through the relay. The typical type of packets is RTP.
Once the connectivity checks will be successful, if the client has elected the relay candidate as the one to be used, then RTP can start flowing. You’ll be able to see the RTP packets flowing in both directions, typically with video and audio multiplexed.
There are two ways for transmitting data:
A Send Indication carries the data (RTP) and destination from the client to the TURN server. The TURN server, granted the allocation exists and the permission allows it, will extract the data and send it to the destination from the allocated relay transport address.
When the data arrives from the remote peer to the relay transport address, then the TURN server, after performing the above checks, will encapsulate the data inside a Data Indication and send it to the client.
There is a more efficient way though to exchange data: the client can define a Channel (through the ChannelBind request), which associates a channel ID to a remote party. From that moment both the client and the TURN server can exchange data via ChannelData messages carrying just the channel ID and data, omitting the remote transport address. This reduces the network and computing overhead and it is typically chosen against the use of Indications.
Troubleshooting points
In the host running the WebRTC client, take a network trace and confirm that data is being sent from the client with Send Indications or ChannelData messages, and to the client with Data Indications and ChannelData messages.
In case of monodirectional media, it’s advisable to take network traces on the TURN server host to clarify whether the media is being exchanged or not on the relay side with the remote peer.
Encrypted TURN
It’s possible to use TURN over TLS, with all the data exchanged encrypted. In this case using Wireshark as described won’t allow you to see the details of the requests and responses, and troubleshooting is harder.
One possible approach is to first of all ensure that all the operations described previously happen correctly when using unencrypted TURN (over UDP or TCP). It’s very likely that the TURN service you are using is accessible over unencrypted UDP (default behavior): before moving to TLS ensure UDP works fine.
Wireshark will show you anyway the TLS connections established with the server, so that will confirm whether the connection was successful, the TLS session established, and some application data exchanged.
Useful tools
Wireshark
Wireshark is available for a variety of platforms; it’s a fundamental tool to understand what’s happening between the local WebRTC client and the remote server.
It comes with filters that detect the type of packets. You can use `stun` to filter out STUN and TURN packets, and even select specific TURN transactions, like `stun.type.method==0x0003` to show Allocate Request and Responses.
Saving a trace into a pcap file and making it available to others helps enormously the ability to troubleshoot.
Wireshark can be used for both capturing and just displaying captures.
There are cases where the dissectors, i.e. the interpreters of the packets, don’t recognize a TURN transaction. For example this happens when they happen over a non-default port (3478 for UDP and TCP, 5349 for TLS). To “help” Wireshark, right click on a packet, select “Decode As…” and set ‘STUN’ as protocol: it will correctly interpret all the packets using that non-default port.
The same applies for RTP: when signalling is not available to Wireshark, then UDP packets containing RTP may not be correctly interpreted. Use the same “Decode As…” method.
tcpdump
On the server side, any tool for packet capture would do, with tcpdump being a common solution.
Save the trace into a pcap file with the `-w` option, e.g. `tcpdump -n -v -w trace_1.pcap`, copy it to your machine and use Wireshark to display the packets.
WebRTC samples, Trickle ICE
This open source tool allows you to verify the browser can correctly gather `relay` candidates with the given TURN server details (URL, username, credential).
Before troubleshooting a client implementation, ensure that this tool can correctly access the TURN resources you’re referring to.
turnutils_uclient
The popular open source implementation of a TURN server, coturn, comes with a tool that simulates a client. A plethora of options are available, allowing you to test specific aspects of the TURN operations, e.g. using Send Indications or using Channels, etc.
Use `turnutils_uclient` to ensure the TURN service you want to use is accessible correctly with the given TURN settings, You’ll also get information about the round trip time and jitter.
Chrome webrtc-internals
When using Chrome, the best way to understand what’s happening is to open a tab on chrome://webrtc-internals/. It will show you all the information related to each RTCPeerConnection being managed by the browser at that point, including the list of ICE candidates, the details of the TURN server being used (except the credential for obvious reasons), including the iceTransportPolicy (‘all’ or ‘relay’), the chosen ICE candidates pair, statistics on media transfer, etc.
Search for `relay` candidates and verify the client is able to retrieve them from the TURN service, and whether they are selected as the candidate pair or not.
Conclusions
This article should provide a good checklist for troubleshooting the connection to a TURN service. There is much more to say, in particular for what concerns browsers different than Chrome and server-side investigations: I plan to write about it in the future.